This is intended to be a post on the process and workflow of establishing a recent AI project within a company environment, based on my experience.
Book Scoring
Briefly, the company I work at has one of the world’s largest grade-level book scorer (second to Lexile), and seemed like a potential opportunity to upgrade the company’s antiquated algorithm with a modern approach.
Personal Motivation:
- Gain more experience on distributed training of LLMs, and modifying LLM architecture.
- Quick turnaround delivering of value to organization.
- Upgrade my own personal workflow with using AI more aggressively than I have in the past, and potentially using this as a showcase to the wider engineering org with lessons learned.
Initial Organizational Motivation: Very little intrinsic motivation, even after ideation/outline-sharing. I argued that eventually, we could update the very manually-intensive process of editing artifacts out of OCR’d book scans, currently limiting us to 2-3 books a week for our most popular product. Not only is this the company’s most popular/identifiable product, also reliant on a very old algorithm (25+ years), and could be updated fairly quickly with modern methods (couple months estimated work) — but I argued this would not be a modernization for modernization sake:
- Because with an LLM classifier, it would give us the potential to trascend the algorithmic approach, and could be trained directly on noisy texts generated from raw book scans (OCR), thus bypassing the intensive manual process of editing.
- Increase our throughput from a few a week to thousands/week. And retask that team to something else.
Challenges:
- Lack of organizational engagement.
- Lack of easily available data (but 250k+ (!) books along with scores, but all edited, no raw OCR).
- I managed to get the editing team to start saving book scans many months earlier but they had only accumulated ~100 unedited books by the time I started.
However, I often find, quick proof-of-concepting something is easier than making arguments.
Process:
0. Project planning:
- a.) Conversations with AI to generate a project specification MD file including selecting the best AI model, and best guesses on the instance costs/type, alternative options and marginal cost differences, etc. This requires deep questioning and directed investigation of the AI agent by you, if you do this — I find relying on the AI’s ‘thinking/instincts’ is not a good idea. Its great at automatically looking things up, collating, summarizing (if it looked up the information), technical writing. Its not great for asking its opinion on things because it will deliver wrong/weakly supported suggestions with very confident language, and misguide you.
- b.) “ProjectThoughts.MD” included things like:
- training parameter/VRAM estimates when considering the open-source LLM I would use (Mistral 7B, for its large context window on a single instance), classifier weights, gradients, # of layers unfrozen, etc
- potential LLM classifier approaches (dense versus an attention-based classifier head)
- planned optimizations and parameters like qLORA, adapter gradients, checkpointing, etc
- book batching approaches (windowed, overlapping/non, first chunk only),
- Cursor-AWS workflow wishlists,
- instance/cost estimates for training,
- other considerations that could be planned for in advance.
1. Set up “AI-based” workflow:
- a.) I set up Cursor with AWS credentials, with an ability to launch EC2 instances, ECR access, along with local terraform, git, etc
- b.) AWS SSM commands (this was critical since many of the other options open up an interactive prompt which Claude/etc cannot interact with; I found it beneficial to specify examples and rules within my MD files for proper AWS SSM interaction).
- c.) An AI agent workflow: edit/write files locally (bash,py, etc), upload them to S3, sync them to instance, run, grab error file/logs/output.
- d.) An AI agent debugging workflow:
- I specified in an MD workflow file to regularly monitor GPU/CPU/VRAM usage, and log output, because the agent tends to (even with guidance) only check process codes and assume success. This was very helpful later as I debugged issues related to loading the LLM (Mistral 7B), large 32k tokens (streaming, batch, single, etc), training/backpropagation, inference/testing, etc. (more discussed in #4 below)
- e.) Some blacklisting (removal from whitelist) of Cursor commands. For example, the AI agent, running into the smallest delay, or transient issue with launching an EC2 instance, would immediately search the AWS account for active instances and try to hijack one of those. Very frustrating until I simply blacklisted the command. Even with redundant Cursor rules and MD file specifications, any long enough conversation would appear to have amnesia for these rules.
- i. From memory (2 months ago), but I had a variety of issues with libraries because I was using an AWS docker image from the AWS ECR repo, which required versioning/installing older libraries. There were other ways around this but I simply stuck with this out of speed/reproducibility priorities.
- ii. Because of this, there were a variety of OOM issues with Mistral model loading during inference that didn’t occur with backpropagation (very counterintuitive) which turned out to be a known bug with a dependent library (I dont recall which one) with fragmentation and memory use during inference. I finally kept the model in ‘training’ mode (capturing the current layers with dropout, setting them all to 0, then reverting after the inference test was run).
- iii. Memory saving parameters to run 32k on single GPU instance (so we could process books), like “PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True”, gradient checkpointing, and others, during debugging on single samples, and then larger batches.
- f.) Some Cursor rules it better responded to by putting them in comments at the top of scripts (rather than MD files or rules).
- g.) MD/Cursor rules for reporting hard observables, not ‘inferences’ or guesses, and actually code tracing, when debugging. Examples:

Some others:

- h) Lots of MD files. I’m sure there are better guides out there. Some examples for this project:

2. Set up preprocessing:
- a.) Essentially a data migration project from a networked single computer, where files were stored in multiple directories, multiple formats, fragmented across files, etc, and putting this all into S3 with cleaner organization.
- b.) Also, pre-tokenizing, capturing relevant metadata, and saving, so training wouldn’t have to handle this.
- This was fairly efficiently handled by the AI workflow with Python scripting within a couple days.
3. Model testing/training:
- Issues as described above while setting up the single-instance training module. Generally, my progression was roughly: (i) get model loaded successfully, (ii) get file loaded, (iii) inference working, (iv) backprop/training, (iv) get a full loop of training/inference working, (v) get multiple epochs working, (vi) optimizations, (vii) view training loss on small set, (viii) training loss on larger set, (viiii) dockerization.
- I had to repeatedly emphasize with the AI agent (with an extensive MD file) for reproduction/reliability of the workflow rather than the agent’s instrinsic behavior to simply patch/debug on the fly, and then declare success and move on.
- For instance, having it restart the entire workflow (or at least go back one step) whenever it thought it fixed it. Including the previous step’s evals/tests that it must pass.
- Actually modifying the workflow/source files rather than just improvising ad-hominem commands.
- Some issues encountered: (when testing LLM architecture loading/LLM file loading/etc on GPU EC2 instances, from memory (2 months ago)):
- I had a variety of issues with libraries because I was using an AWS docker image from the AWS ECR repo, which, due to dependencies, required specific versioning/installing older libraries. There were other ways around this but I simply stuck with this out of speed/reproducibility priorities, and under a mistaken belief that this would enable me to use their services (AWS Batch, etc).
- A variety of OOM issues with Mistral model only during inference, but that didn’t occur with backpropagation (very counterintuitive), which turned out to be a known bug with a dependent library (I dont recall which one) with fragmentation and memory use during inference. I finally hacked around it by keeping the model in ‘training’ mode (capturing the current layers with dropout, setting them all to 0, then reverting after the inference test was run). I later saw this was a many-month-long issue in 2024 that got patched in more updated libraries I wasn’t (and couldn’t) use.
- iii. Memory saving parameters to run 32k on single GPU instance (so we could process books), like “PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True”, gradient checkpointing, and others, during debugging on single samples, and then larger batches.
4. Distributed instance setup: I spent a large amount of time trying to get AWS Batch to work, then ended up setting up my own scripts. Features like:
- Auto-resuming/auto-advancing past the last sample on repeat crash/restart (along with a crash detection/restart in the distributed script).
- Timeouts, attempting to restart the instances before relaunching.
- Proper mount/permissions/log capture of master node and a worker node.
- Checks before advancing to the next step.
- I ended up using torch.distributed (DDP/NCCL), but don’t recall what other options I considered or tried.
- Distributed was worth setting up for the PoC stage (despite some engineers saying it might not be) because it cut our training from 2 months to 2-3 days (while adding about a week of dev time).
5. Data science/analysis
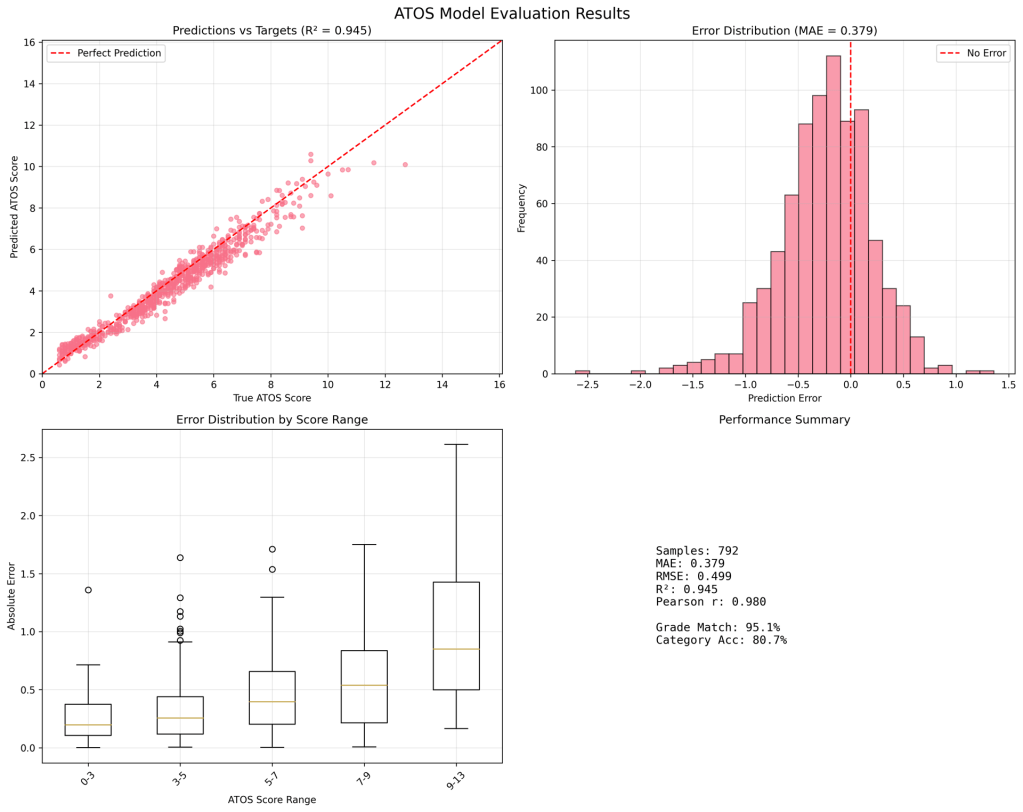
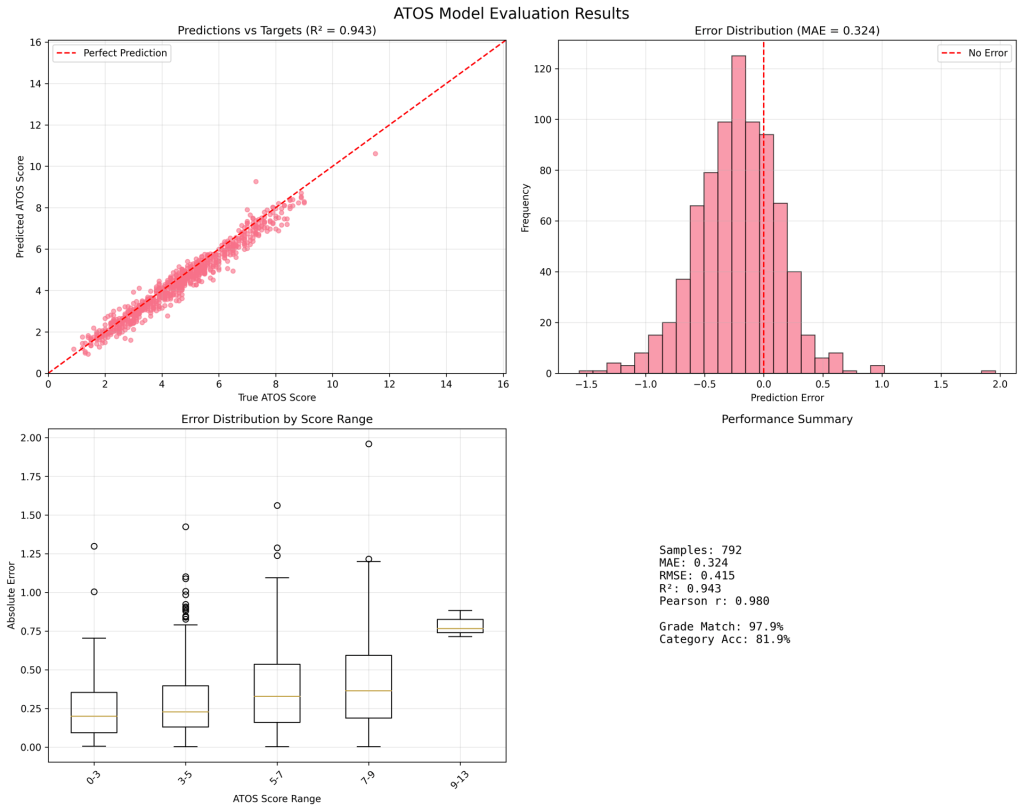
- a.) AI workflow is exceedingly fast on this. Can generate scripts that produce numerous graphs (decently labelled, although some irrelevant views) and statistics on reserved inference test set. After a larger distributed run (I used 16 GPUs, for ~2 days), I trained it on ~180k books with very good performance on test set (also showing the worst performing samples, only off by ~1 grade level).
- b.) A clear progression as more data was trained:
80k books:
160k books:
- c.) A test of the ‘reserved’ uneditted books (only about 150 books) which showed, as expected, worse performance (couple grade levels off).
- The good news is that the error was in one direction (model consistently underestimated), and highly corrrelated (ordered correctly), so not just pure variance.
Leadership Communication — At this point (about 4 weeks from inception), I could communicate this PoC to leadership. Roughly, some points were:
- Demonstration of organizational dataset we can leverage (and other potential datasets).
- Demonstration of workflow for engineers;
- Demonstration of value of LLM classifiers for other potential applications in the org
- Demonstration of increased throughput (from 2-3 books a week to thousands);
- Demonstration of organizational resources saved (although arguably a small team) that could be tasked with other projects;
- A book assessment pipeline that could updated in the near-future (operating accurately on uneditted books, I will detail below);
- A pipeline that could be updated to be tasked for very large Curriculum teams in organization (quiz generation, content generation, etc) for an in-house “readability” score which shows what grade-level the content is written for and part of the audit process for content.
Proof of concept/”good enough” — I could have trained this model for more epochs, but the trend of training loss was clear enough, and the proof-of-concept was tangible enough for me to present to leadership and generate broader motivation. This might seem obvious in hindsight that this would work, (and many engineers would give a reductionist argument that this a simple human task/algorithm, therefore even a simple LLM could handle it, but I was skeptical). But I worried about theoretical challenges for this LLM Classifier task:
- Lots of metadata/title/inner book cover language and info that could throw off the classifier. Plus, hypenations, captions, other artifact noise.
- a.) I believe the architecting the classifier head with an attention mechanism rather than a simple density head helped this. I did not collect extensive data on this in the PoC stage, other than to note that with small samples, the attention head approach took longer to reduce in training loss than the density head. I assume the attention head mechanism in the custom classifier head allowed it to ‘ignore’ the variable amount of irrelevant data that could be included in the PDF OCR text.
- LLMs are notoriously bad at ‘counting’ letters, syllables, etc which is a significant component of the grade-level scoring.
- I thought with a large enough model (Mistral 7B, 32 layers of attention, 32k context window) it would be deep enough to detect these patterns that I would guess would show up in much later layers (if we were to run an Intrepretability project to figure out where this concept gets represented), thus making a smaller network more likely to be more inaccurate.
- Greater transferability/fine-tuning potential later on.
- Larger LLMs inherently have a larger knowledge base of semantics, vocabulary, concepts — so ‘readability’ tools later (for our quiz/lesson content) could be based on this work which leverages a quarter million books.
6. Synthetic Data to train it to deal with directly OCR’d books (not edited)– I won’t spend too much time on this other than to say I used the AI workflow (with lots of back-and-forth questioning of its (a) implicit assumptions, (b) laziness, lack of actual checking, it reflexively makes) to ID a long list of artifact patterns when comparing some of our training set (uneditted files) against a portion of our small reserved dataset (editted files). Then directing the AI agent to write a script (using our worfklow) to produce these artifacts in our large dataset, along with a de-tokenizing/re-tokenizing script workflow. Then rerunning/resuming our distributed training pipeline on these ‘noisy’ files. Then testing against the other portion of our reserved dataset.
7. Retooling/double-serving as our Readability Scorer — Shortly later, I was able to leverage a large internal quiz dataset (100ks questions) that weren’t explicitly labelled for readability, but have associated skills –> standards –> grade levels, that I could use to roughly train (fine tune) the LLM further on shorter text inputs. To be used for our manual workflows in our content teams, and as an element in our new automated AI agent content (I will detail in the next post).
8. For productionalization, this is still an internal tool, but batching (for cost-saving, and for book scoring which are not time-dependent) and leveraging single-instance instances/runs (which is what the project was designed for).
Conclusion
This project took two months (burdened by some other work in parallel, I’m the lead ML for the division; along with some delays due to organizational ops access [locally stored data I eventually migrated, account permissions issues], some wasted time trying to get AWS Batch to work before implementing my own distributed pipeline, and wrangling this project’s workflow entirely through Cursor (as a personal experiment). This leverages the value of a couple large internal datasets, along with modern open-source LLM capable of 32k on a single GPU, and a fairly modern AI workflow.
(I will write on the second project, “AI-fication of educational content generation”, in the next post)
