[Reposted from 2019 in response to Google Deepmind team releasing a comprehensive AI for Starcraft 2]
2/12/2019
The Event: DeepMind (Google’s AI team run by Demis Hassabis) tested some artificial agents against two high-level professional Starcraft 2 players this week and essentially won all the matches.
Me: I watched most of the matches, and read the press release/blog post on DeepMind’s site. I have a background in machine learning, cognitive neuroscience and am familiar with this game. I wasn’t planning on writing anything but saw too many “machines beat humans” headlines and was compelled to spend my Sunday evening beating back the hype.
My main issue is with the lack of understanding by the AI community of human decision-making when making claims of AI ability (vs humans) using this task (StarCraft 2). [Feel free to jump to my main criticisms.] The reason human decision-making is relevant to the decision making of this bot is because:
(a) They are not making explicit comparisons from this bot to other bots, but rather (in the media and press releases) bots to human beings (and in this event/experiment, literally, against human beings).
(b) StarCraft 2 is a motor-perceptual-cognitive task designed for humans, so how it is played is extremely relevant if we want to make statements about the cognitive part. Imagine we were trying demonstrate the superiority of human reactions on caffeine vs another group of humans off caffeine, using this task, but we gave the non-caffeinated human team an Xbox controller to play this game (which would severely limit their ability to make actions in a strategy game compared to a mouse and keyboard), but then insisted that this significant disadvantage doesn’t negate our ability to say something about the caffeinated state. This is akin to many statements that are being made about this DeepMind AI bot.)
(c) Human decision making will continue to be the main relative benchmark to compare with for a while because we don’t have good absolute scale (say, a mathematical one) of what constitutes a good move in NP-hard space. This point gets further emphasized given the potential psychological game that is involved with games that are information-incomplete and interactive with competitively adapting players.

Prepare to tactically jump. All over this event.
OBSERVATIONS/REACTIONS:
(1) Firstly, it’s very cool amount of progress.
I remember a year ago when they released some unimpressive-looking (at least to a player/consumer; more impressive to a programmer) “training exercises” where the agent was simply able to select and move a few units on a single screen. In this week’s demonstration, they played out full games where the bot agent could conceivably handle anything from a mineral-blocking-pylon-gateway rush to a multiple-base-expand type of macro game (although we saw five cheese-free relatively straightforward games from two different pro players). I do think it’s worth noting that if this ever gets publicly released, the population of human players (or pro players) would be more free to test unorthodox strategies against it and potentially finding weaknesses in it.
(2) The DeepMind blog showcased some advancements/changes in neural network architecture (including a link to a paper on “pointer networks”, which I had never heard of before — sort of looks like an RNN, but with more hierarchy) for this project.
It will take some time for these to be developed into tools, tested in labs and in industry, and to be seen whether these changes truly confer advantages in real-world problems (and which ones). However, I’m drawing attention to this aspect of their recent release because they do try to operate more like a laboratory trying to push forward new tools. (Conversely, they could have only worked on the interfacing layer between the agent and the game, applied existing neural network architecture and made a thousand context specific tweaks to their training sets and the networks themselves, rather than exploring new architectures.) Instead, they could explore ‘the brains’ rather than the interfacing, thanks to many developers and Blizzard for the tools, although I’m sure it still had it’s share of headaches
(3) It was cool (yes, I keep and will keep using that word because I think its all very cool) to see some game streamers I watch and their audiences being captured by an event that falls in the realm of neuroscience and computer science.
The clashing of machine learning (which I spend a lot of time in) and some of my entertainment hobbies, has energized me to the point I decided to spit some thoughts down. Like many people, I thought this event represented an intersection of many different interests I have. For my graduate dissertation, I wanted to bring in expert StarCraft players and scan their brain in an fMRI scanner while they played because I thought Starcraft, as a cognitive task, was capturing a variety of interesting and complex cognitive human behaviors (including very high-level multitasking, decision making, perception, predicting with information uncertainty, etc) that also has a very high skill ceiling without the monotony of laboratory tasks.
(4) The deliberate fantasy-warping of “AI” is annoying. I’m not a fan of exaggerated claims about it nor am I fan of it being projected into future Earth-ending possibilities by the media and popular science-orbiting figures.
To me, the public image of what is, essentially, computational-automation-technology comes off an annoying combination of cynical manipulators and bad fiction writers. But I’ll admit, as I was watching the DeepMind agent deftly stutter-step Stalkers against a 6000+ ELO human global outlier of Protoss-controlling expertise while brazenly producing excess probes rather than defending them, I did find myself referring to it less as ‘the bot’ and more as “the AI.”
(5) I admire DeepMind’s initial attempt to center this project around artificial decision-making by limiting the AI to human-level perception and action, but I think its insanely misleading for several reasons. (Skip down to my main criticism)
Ultimately, Starcraft 2, a highly demanding motoric-perceptual task may be the wrong game to use to say anything about decision-making. Simulating a human-equivalent interface for the AI may be too costly for the AI community to focus on, which is what is required to use this task (SC2) to answer questions about human vs AI decision making.
I keep reading/hearing statements that the AI’s superhuman abilities to take in information and deploy actions (APMs) can’t take away from claims made about its decision-making. I think there is a lack of understanding of the perceptual and motoric limitations of humans by the AI community (which our brains optimize for), and without understanding that, without separating this from the task, the event had very little to do with showcasing superior decision-making.
(6) I think there is a small but important point for the eventual use of AI as generating automated, and thus less biased, metrics of human performance/behavior, particularly in highly complex environments or tasks.
In general, I think this event provides yet another example on the state of artificial intelligence as a way of capturing big data patterns that is beneficial because it is automated and not “intelligent” or finding novelty. The extent to which it is automated, given the amount of manual work that had to go into this could be questioned as well (DeepMind employs 700 people on a ~$300 million annual budget although I assume the team size for this event is much smaller). But if these tools become more deployable, their automated nature will one day allow us to run millions of cross comparisons thus generating quantified measuring yardsticks for ability in complex settings (much like they did in this event with Estimated ELO).
CAVEATS TO CONSIDER (or “experimental limitations”, if you’re using science lingo):
(Caveat #1) It was set-up to run for only one of the match-ups (Protoss vs Protoss) out of the nine possible by the game (sixteen match-ups, if you include ‘Random” as matchup: for Grandmaster-level random matchups, check out WinterSC on YouTube and Twitch). It is only been trained on one map so far.
- From a project management point of view, there is nothing wrong with this limitation. Often, you need to start with a specific part of a problem and generalize out from there. I think DeepMind’s restriction of the problem space and approach makes sense.
- But it is worth noting that this is another example of the insane amount of crafting required by humans (a team of at least a dozen PhDs, working for a year) to make these automated bots (to play on one map with one race), is an insane leap from some sort of self-evolving, self-coding, philosophizing, generalized, new-race-of-bots-replacing-human intelligence excitedly described by certain pop scientists, commentators, and certain corporate industrialists.
- Beyond the scope of this article, but I think there are reasons for the mis-characterization of what is, really, advanced automation within a specific context. I will summarize my thoughts as to say, I think its due to a convergence of (a) financially-motivated hype to attract investors, (b) cynical attempts by the early players to manipulate the government into pre-regulating an eventual trillion dollar industry, (c) self-promoting commentators trying to sound like oracles to the lay public by repackaging scifi tropisms of an obviously popular trend, (d) genuine confusion and misunderstanding, and (e) the understandable tendency to try to entertain ourselves by matching the stakes of scifi/fantasy plots to the world around us.
- Because the specialization required, AI agents may end up representing the vast majority of a game package downloadburden in the future.
- Blizzard had a workshop at GDC 2018 (Game Developer’s Conference) last year where they showed the community how to use the open-source tools to build an SC2 agent they were using for this project. Other games that presented at GDC last year already have commercially available AIs packaged with them that already represent the majority of its download burden (e.g. “Race for the Galaxy” is a card game that gave a presentation at GDC on its approach to making a neural network for its game. They reported that they created two dozen separate AI agents, one for each possible match-up in their game that was something like 80% of the download for their game.).
- Finally, again, please do note the distance between this specialized automated bot (a manually curated set of specialized Protoss-vs-Protoss-on-the-Catalyst-map-in-the-game-of-Starcraft-2-hooked-up-to-specialized-interfaces-customized-for-it-trained-with-a-series-of-customized-exercises) from the, often referred “AI” with its generalized ability to become rapidly good at any domain as long as its hooked up to it.
(Caveat #2) One of the professionals (TLO), had to play his non-main race (that is, the set of match-ups he doesn’t specialize in as a paid competitive individual) because of these match-up limitations of the artificial agent.
- The DeepMind team handled this by estimating the ELO (basically, your playing ability based on your wins/losses and the toughness of opponents you’ve beaten; they use this metric in chess) of their collection of agents in advance and attempting to match him up with one in his ballpark. Presumably, they did this with his Protoss ELO.
- I like this project because its one of the first examples of something I’ve been hoping for, for a while: psychometric characterization of artificial ability/complex tasks. When I saw they had dozens (maybe hundreds) of individual agents, all with estimated ELOs, my thought is that this will be a very powerful tool in the human sciences to study human behavior.
- If you care, what I mean by psychometric characterization is that using psychometric math, individual questions (on a standardized test like the SAT or the GRE) not only get rank-ordered by difficulty, but also show you how confident (or how much information) each question provides you in regards to ranking someone’s ability. What DeepMind currently has, is the metaphorical equivalent of potentially, thousands, of “SAT” questions, each containing a complete but distinct (even if barely so) strategy to be tested against. What this may provide in the future, is an automated (not human vs human) way to accurately assess an individual’s ability in an extremely complex task situation. There are caveats you could imagine to this (e.g. consistency due to human fatigue, potential ‘rock-paper-scissor’ type scenarios where the rank-ordering of player strategies isn’t necessarily one-dimensional but circular, etc) but I believe research labs will eventually use this approach in sociological, psychological and cognitive areas (to study human decision making, human behavior in negotiations, other game theory social situations,, etc).
- At first, I was surprised they showed up with so many agents. I was imagining the pain the DeepMind team probably experiences, with a mess of project files with versions labeled “1.2.34.b” and “1.2.34.b.a”, etc. The lack of a single coherent agent reveals the messy science project it currently is. On the other hand, competitive or evolutionary environments (where you keep redundant copies of the thing you’re trying to design, allowing them to diverge, be tested against each other, and sometimes recombining the traits of each other) probably represents one of the eventual ways forward in this field.
(Caveat #3) This event was a master class on how NOT to conduct a psychological experiment.
Look at this video link: https://youtu.be/UuhECwm31dM?t=107
Poor TLO. You can watch him smile every time the room of thirty humans next door cheers loudly whenever the bot wins. Insanely intimidating. No supporting teammates. No real financial or social incentive for him to win. Massive sociological incentive for him to lose.
Putting all this aside, not blinding participant’s to the experimenter’s bias or goals is the number one reason psychological experiments have a reproducible crisis. You can see the insane bias in this video.
Why is this relevant? Maybe this was just a friendly PR stunt and experimental standards are irrelevant to this. Well, feel free to bookmark this page and return once they get their publication accepted in Nature or some other scientific publication. (Their entire blog page basically reads like a pre-print Nature article, replete with an intro and figures: https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii/)

By using Mana and TLO as baseline metrics for their agent, they are making explicit claims that fall into the realm of human cognition, psychophysics, and behavioral psychology that demand some minimal standards of data collection (for instance, having them play many games against humans and AI, blind to which they are playing against). Simply, you cannot use humans as a tape-measure to measure AI ability, if your humans are unblinded to what their host wants.
The reason the collection standards are ridiculous is that if the data from this PR event are published as a scientifically-collected evidence of superior decision-making against a high performing human, they will then be used to fuel a popular perception of a “superior decision-making AI” (that the general public will see is backed by a credible scientific journal reference).
(Caveat #4) Why its not really superior decision making: Actions per minute (APM) restrictions, insanely high quality APMs, and information advantages.
They reported that the agent was APM-restricted (actions per minute) to ‘human’ levels. The few times I looked at the APM, it did seem to be reasonably restricted (I did see some spikes, by the human and the bot up into the high hundreds — but nothing superhuman like 10,000 APM — at least that I saw). This was a superficially reasonable imposed condition by DeepMind because if the goal really was to compare humans to AI in a real-time ‘strategy’ competition, its good to not have the computer simply blow over a human because it can make a million moves a second. (EDIT: I was pleased to see others going into more detail about whether APMs are really human level because of ‘burst’ APMs.) However, even if number of APMs were capped to human level ability, I still have other concerns with the interface the AI was using.
More deeply, DeepMind’s stated goal with this project is to compare ‘decision making’, to see if the computer can make higher quality decisions than professionals that have logged tens of thousands of hours, compete and beat the entire planet (essentially) of millions of other humans, and are paid for a living to do so. Higher quality decision making is a great goal but this requires you to deconvolve decision-making from motor and perceptual superiority. For one, I’m highly suspect that the computer’s ‘APMs’ are just insanely advantaged by the specialized set of tools Blizzard made that allows the bot to interact with the game (often, in a highly advantaged way compared to humans).
In fact, this is where the majority of my caveats kick in:
- (1) Perceptual bottleneck: The AI was looking at the whole map the whole time. That is, the AI didn’t have to switch screens (essentially, the complex second-to-second meta-perceptual task of alerting-and-orienting the tunnel vision of human sight to whatever part of the map needing to be looked at, that we call attention).
- First, for the actual event, they ended up showcasing a project which “relaxed the screen-view constraint,” and just allowing the computer to see everything everywhere all the time with a zoomed out view. There are games like Supreme Commander which allow this kind of view but StarCraft 2 has view constraints that the human players are forced to contend with.
- They have referred to a “minimap feature transpose” as a reason the bot didn’t need to switch views, but for a legitimate comparison, this would require the human view to have a blown-up view of the small pixels on the minimap (which you can do through the interface in a game like Supreme Commander). Otherwise, in the game of Starcraft, you are still required to check a screen to update new information wherever there is congregation of units (showing up as a blob) or units are dipping in and out of the fog of war, or because new events have happened or could have happened. This costs a human APMs to simply look. Arguably, this isn’t an AI vs human difference but the difference in the essentially different games the human and AI were respectively playing.
- This was more apparent as only the final match was against a bot with this single-screen limitation (that a human has), and succinctly lost to the human (and looked like it’s entire army was stuck by cliff trying to kill an air unit).
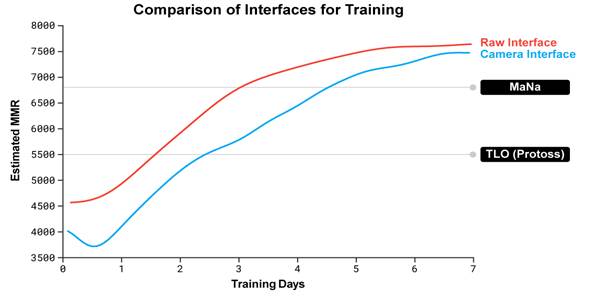
This is the data they showed to argue that “camera interface” restricted agents are essentially “equivalent” to the raw interface agents, despite the ‘camera’ restricted agent losing pretty clearly in its only game. In fact, using their own equivalence argument, you could claim the single data point of the Camera Interface agent (which lost 0-1) proves that the decision-making abilities of the Raw Interface is, at least, less than Mana’s since he beat it 100% of the time.
When you decide to look somewhere in SC2, understand that your brain is crunching Bayesian-level probabilities to make decisions aboutwhere it will likely find salient information. This decision (followed by a hotkey press, or mouse minimap-click action) happens in order to just get the information (which you haven’t even processed, yet, much less reacted to) and can sometimes result in wasted APM just looking at dead zones or where nothing happened (nothing wrong with your brain necessarily; its just that its a probabilistic problem, the problem is time-sensitive, and the game has imperfect information). Skipping this part with a superior interface results in less required decision-making.
- (2) Motoric bottleneck: The above point (screen switching versus a zoomed out view of the whole environment/map) refers to the perceptual bottleneck humans have to work with in this game. Another problem was the motoric bottleneck (that is, actions by your hands/fingers/etc, through the mouse and keyboard).
While I don’t think it is at all necessary to simulate a robotic hand on a keyboard, I do think that if they had limited the selection and action points to a lower number, it would have been a much more convincing display of “superior decision making.”
For instance, force the AI to have to decide, moment to moment, to make an individual unit action or group-select actions. For example, consider the levels of decision-making a human brain makes, given their fingers/mouse/keyboard, when engaging in a firefight with a large group of Stalkers:
[A] The human can try to save a couple individual ones (by individually blinking them back), maintaining attack pressure but having other individual ones die because there isn’t enough actions/attention to go around to save them all in those precious seconds.)
[B] The human can group-select, blink all the Stalkers back, thus saving more of their units, but letting off pressure on the opponent.
[C] The human can try one of these strategies, monitor, switch to the other when losses are too high or damage on the opponent is too low.
This is an example of one of the many meta-decisions humans have to make, being aware of their own motoric/interface limitations. Some deal with this by keeping the units nearby enough not to lose that many, but not attacking either (kind of a soft “pressure” on the opponent), while focusing their motor actions and attention on their economy to produce more units. This is an example of a decision. Doing everything you want because you are enabled by a superior interface is not a decision.
This problem was particularly apparent to me when the AI was ‘blinking’ individual units (Stalkers) back right before they died — sometimes several within a second, all while group-moving a couple armies. The issue is, while, yes, a human can move their mouse, select an individual unit, press the hotkey on their keyboard, move their mouse location to the back of the group, and click in a pretty small amount of time (especially a professional player), it appeared to me that the computer was doing this faster than what is possible by a human. The transit time of the mouse position alone (much less to slow down near the target and do it accurately), without fatigue, while switching to factories back at base to queue up more units and workers, seemed clearly superhuman (to me at least).
- This was convincingly apparent when (I believe in Mana’s Game #5?) the AI had pincer attacks with two groups of Stalkers off screen from each other on the human (bringing me back to the perceptual problem above) where a human would have to also switch screens back (requiring at least an extra hotkey press, and reorientation) and forth at an insanely high rate to monitor all of that, much less influence with individual unit commands.
- EDIT: I found a really good video analysis (linked to his description of the AI in Game #5): https://youtu.be/sxQ-VRq3y9E?t=502
My point being, given the number of motor actions a human needs to make to actually send a precise command (arguably, upwards to half a dozen for one action) because of the game’s interface, they needed to, at least, greatly restrict the APM output. At best, they would be able to simulate the interface that a human has to use (which is a huge part of this cognitive ‘decision making’ task).
- (3) Cognitive: I’ve addressed the perceptual and motoric problems. The final point I’ll make (for now), is the decision-making element of this Human vs AI test. The problem is that the human player had exactly zero games against this agent or type of agent prior to this test. This may seem like a weak point but its actually a fundamental game theory advantage the bot had (that will only weaken for the bots as they are released into the public). A true decision-making test would be both players (human and AI), having matched experience with (or just be blind to) each other’s tactical tendencies. But, in this case, the bot was able to study thousands of human replays on this map of high-level humans playing, whereas Mana never saw a single game from this bot before. This is a bit equivalent to a card game competition (Magic the Gathering, Hearthstone) where your deck is public and study-able before the event and your opponent’s is closed/sealed and thus, a mystery. As Mana commented after the event, he became very aware during this competition of how much his gameplay relies on forcing human mistakes. My point is that these bots play differently because their eyeballs and fingers are different (whole map, instant unit control), and humans haven’t even had a day to figure out how to beat that prior to this competition. As a test of decision-making wit, this event really wasn’t a good test.
- Additionally, during the test, the agent would be switched out to never be played against again. As a “best of five” decision-making test, it didn’t even afford the opportunity for the human player to poke the same machine for even a second go-around and figure out its particular weak points. The counter argument to this, which is reasonable, is that the agents may not be very distinct from each other. Given the Stalker-consistent play, I think this may be true as well. I can understand that if I were a scientist on their team, I would want to capture as many datapoints as possible in this event against a varied spectrum of agents they created.
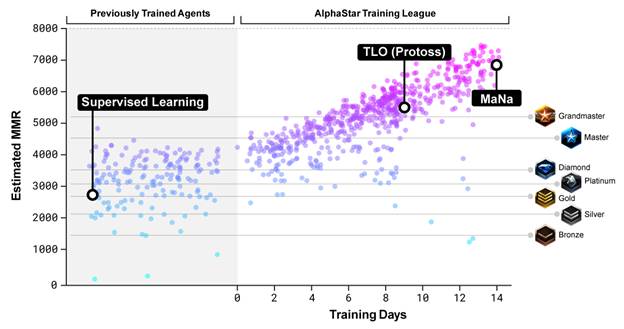
However, the problem is that the strategy switches are not AI but humans that are switching up agents representing individual strategies and play styles. Strategy switches can represent the primary way high ELO players beat each other in best of fives/sevens. The disingenuousness of the press releases will make people think a “best of five” was conducted by a single agent operating free of human influence, deftly switching strategies game to game, psychologically analyzing the tendencies of TLO or Mana, and crushing them with their own weaknesses in subsequent games.
Scientifically, the problem is because of the (a) game theory advantage the bots had, and (b) the manual strategy switching by the DeepMind team, this event doesn’t represent a robust test of “artificial decision making”, even within the map-constrained, race-constrained parameters, interface-enhanced parameters they had.
Getting this to work at all was an achievement in itself. As an engineer, this project looks fun to work on and intellectually engrossing, starting with an, essentially, agnostic pattern-extracting architecture, and trying to coax it to realize the many layers of patterns to be found in different scopes of StarCraft (unit control, tactics, and overall strategy). As someone who appreciates games, the possibility of way more complex and more ‘human’ AI in future games is exciting. As a scientist, keeping an insanely complex project like this under control that probably threatens to constantly logistically spiral out of control and never even come close to working is beyond impressive.
However, as a science project, they have almost all the way yet to go to show any superior decision making against humans. We don’t really know if continually producing probes and not defending its workers is a superior decision (as the agents appeared to do consistently against the human player). We really don’t know if Stalkers are almost always the best unit in a PvP match up, even against Immortals. Or if a pylon-gateway-pylon-stargate proxy rush (as one agent showed, to the best of my memory) is an actual viable strategy, because of the conditions of the game that humans have optimized to were changed to something else for this event. We just don’t know if you spent tons of resources improving the human side of the interface so that they were essentially playing a different game, would they still lose against these automated bots?

Visions of a 10,000 ELO StarCraft player. Bring it, AI.
If the awe of watching automated Stalker micro still makes you question my point, consider even the last game where a simple dropship caused the Stalkers to congregate uselessly near the cliff. There is little to suggest that there isn’t a myriad of clever ‘troll’ or ‘cheese’ builds that humans could yet throw at this set of regression equations. Consider what would happen if you allowed the game to be played at 1/10th speed, and allowed a human to make actions, pause it, come back to it, over the course of a week? Are you still confident that the AI decision-making would hold up?
I think there does represent a possibility that the game is complex enough that humans haven’t converged on an optimal ‘meta’ (that is, a set of optimal strategies). It is possible that there represents some hidden tiny but deep valley on the abstract topography of strategies. Its also possible that humans, as a collective intelligence, actually did already ‘solve the meta’ (at least every time a new patch/map is released). But that is not what this event ended up giving us any clues to.
I think the interesting question is: Compared to a human brain’s ability to build a decision tree/map in a highly complex environment with imperfect information, can an artificial bot agent do the same or better? Even if you grant it the manual tweaking by a dozen experts for over a year focusing on the specific context of a single match-up and a single map — allow it to log in ridiculous amount of practice and experimental time (reportedly, 200 years of playing) against itself and other agents — even with all that, can it arrive, on its own, (that is without human lessons teaching it), a superior decision strategy tree that truly reflects higher intelligence?
Or does it need all the above, plus inhaling all the lessons by the totality of the human population and our highest level practitioners in the form of replays?
Or does it need all that plus relying on perceptual and motoric advantages conferred by a specialized set of interfacing tools? The reason this final question is less interesting is that it then begs what a human brain could do with those advantages (e.g. optimized interfaces, better education), if we bothered to spend our efforts creating those instead, and undercuts the entire AI-as-a-superior-intelligence hype.
If that final question is the actual scenario we are dealing with, then AI’s destiny is to become more of a scalable, reliable-enough presence on this planet, relegated as another type of automated cog in our industrialized world, rather than the alien presence, super-intelligent god, or weaponized threat people with megaphones like to claim. I would argue that, with regards to the decision-making tools that will be eventually available to us, human and AI, what we will really have is something less like complete dominance, and something closer to the asymmetries found in the Protoss, Zerg and Terran of StarCraft 2.
