(Previous blog post on AI evals here: Validation Process with Agentic LLMs/Context Engineering)
This post is about how to integrate expertise from Subject Matter Experts into AI systems.
- Imagine you have a team of SMEs generating content by hand currently. The 2026 problem is how do you explicitly codify their intuitive/unarticulated criteria/processes into explicit LLM-friendly instructions?
- This is solved with either of two types of inputs:
- Have them supplement criteria, instructions, processes — which is used in an semi-automated meta-evaluation loop (this post)
- Have them supplement examples (future post) — which is used in a more sophisticated automatic meta-evaluation loop
.
Getting Started
The essential directed workflow using an AI agent to get started is:
Research –> Scenarios/Metrics (+ Modes) –> Master System Prompt
You can direct the AI (or group of subagents) to aggressively tackle each one of these to get started. I used this essential workflow a year ago for engineering tasks (project approaches -> possible features/scenarios/problems to be solved –> unit tests + project specifications) when directing AI to make plans. The Claude Code superskill feature does a decent job of this in 2026.
For our example, we execute three AI-driven phases: (1) Research effective pedagogical frameworks related to digital tutoring, (2) Craft scenarios and metrics based on that, (3) Create a master prompt based on that. We can revisit these phases and add more later on as well.
.
Evaluation Loop
Now, we want to establish our evaluation loop:
[Scenarios + Metrics + Modes] + [Master Prompt] –> Evaluate –> Evaluation Results
This means:
- Metrics: criteria (how will it be evaluated, using an LLM and/or tools), threshold (% of passing cases)
- Scenarios: test input and expected response. For this project, we have dozens of categories of scenarios ranging from AI Safety (appropriateness), to Learning Effectiveness, to Engagement Maximization, etc
- Modes: we ended up super-categorizing our scenarios into two categories (multi and single-response). On other projects, this could be environment differences, content types, etc.
- Master Prompt: the thing we’re trying to optimize.
- Note: We are tabling fine-tuning as another optimizing knob for this post but this should not be overlooked.
- Evaluate: Without overloading this post with technical details, I’m using GEval formatting, a custom harness, and a better LLM than the tutor (which is optimized for cost since it will be called so much).
.
Meta-Evaluation Loop
(with a non-technical interface for a Subject Matter Expert (SME))
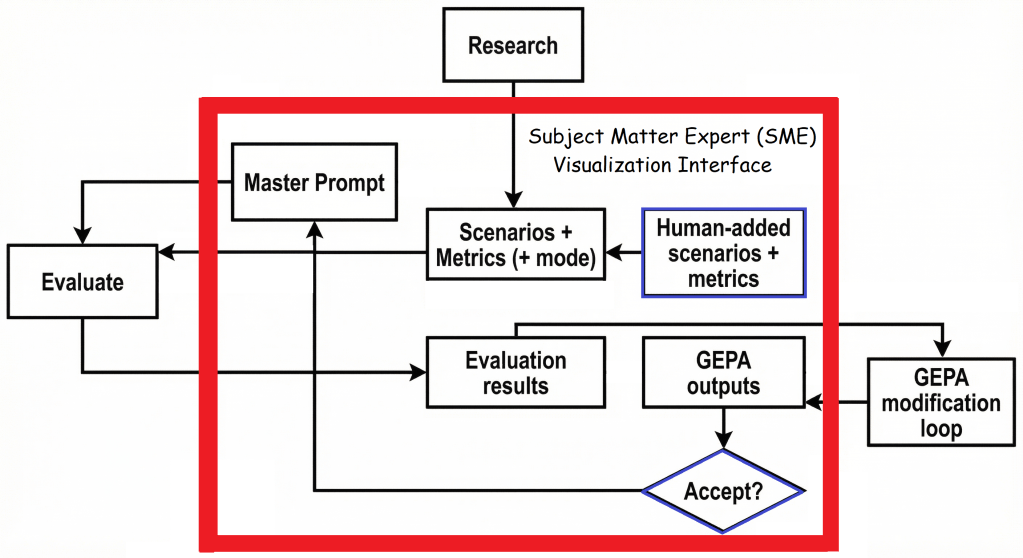
- Most of the boxes reflect information for the SME (Scenarios + Metrics, Evaluation Results) to review.
- These existing inputs (initially AI generated) can be reviewed by the SME and reviewed for potential gaps, etc.
- Not in the figure, but also included, is the outputs for each scenario and metric if useful to the SME.
- The SME adds their own SME-added Scenarios + Metrics (blue), and can run Evaluate loops, and examine the Evaluation results. (Also modifying or eliminating existing ones if desired).
- If the SME likes the outputs, they can run an optimization loop.
- In our case, we use “GEPA” (Genetic Evolutionary Pareto Assessment) which essentially trial-and-errors new versions of you master prompt (literally by asking another prompt to fix it), tests them via your evals, and uses basic pareto scoring to select the best Master Prompt. This is non-convergent and simply runs until the default or set number of runs is finished. This can obviously get expensive.
- You could use any other prompt-modification library, there are others out there.
- In our case, we use “GEPA” (Genetic Evolutionary Pareto Assessment) which essentially trial-and-errors new versions of you master prompt (literally by asking another prompt to fix it), tests them via your evals, and uses basic pareto scoring to select the best Master Prompt. This is non-convergent and simply runs until the default or set number of runs is finished. This can obviously get expensive.
- The SME can look at the new optimized Master Prompt but its probably not that relevant to them. They can look at the new Evaluation results for the new prompt, and the raw responses, and Accept (blue) it.
- They can repeat with new metrics, scenarios, or research-based directions (focusing on Engagement or Exploitation issues, instead of Learning Efficacy, etc).
I find this interface can be mocked up easily with scripts and a few workbook sheets but you could make it more fancy if you wish.
.
More definitions

.
Future
I didn’t cover:
- Integrating fine-tuning (article here on how to set up your own fine-tuning if you don’t want to use the tools/APIs which keeps the models on Anthropic/OpenAI servers and limits your model adaptation by freezing nearly all the weights)
- Integrating a multi-agent network of experts
- Adapting the metrics and scenarios automatically
- Categories of scenarios/metrics, AI Safety issues, effective tutoring & engagement, etc
.
Conclusion
This will get you started with a clean framework and way to think about it. I spend a fair amount of time explaining to teams that taking time to integrate knowledge workers (SMEs) directly into the workflow is superior to a slow, iterative, hand-off process (between engineering, content, and PM teams) which often kills projects fast.
The goal of many AI development projects is essentially automation of previous human work via transfer of knowledge, so a robust process should be engineered to facilitate this knowledge transfer.
With tools like Claude Code, you can mock these tools and frameworks up in days to weeks.
