(5/26/2026) Small weekend project to explore some AI Interpretability methods. Summary and github below.
broad tl;dr: Traditional LLM interpretability relies on “bottom-up” feature discovery (finding features then labeling them:
- finding Sparse Autoencoder (SAE) features that fire maximally to a single stimulus,
- scanning large datasets for text that activates those features most strongly,
- then using LLMs to identify common patterns and label what the feature represents),
but this project explores “top-down” feature targeting (hunting for specific semantic concepts using stimulus-response mapping:
- starting with a specific semantic concept you want to find,
- creating stimulus-response datasets that represent that concept,
- then using various analysis methods like RSA/cosine distances + statistical tests, to identify which neural features best discriminate or represent that target concept).
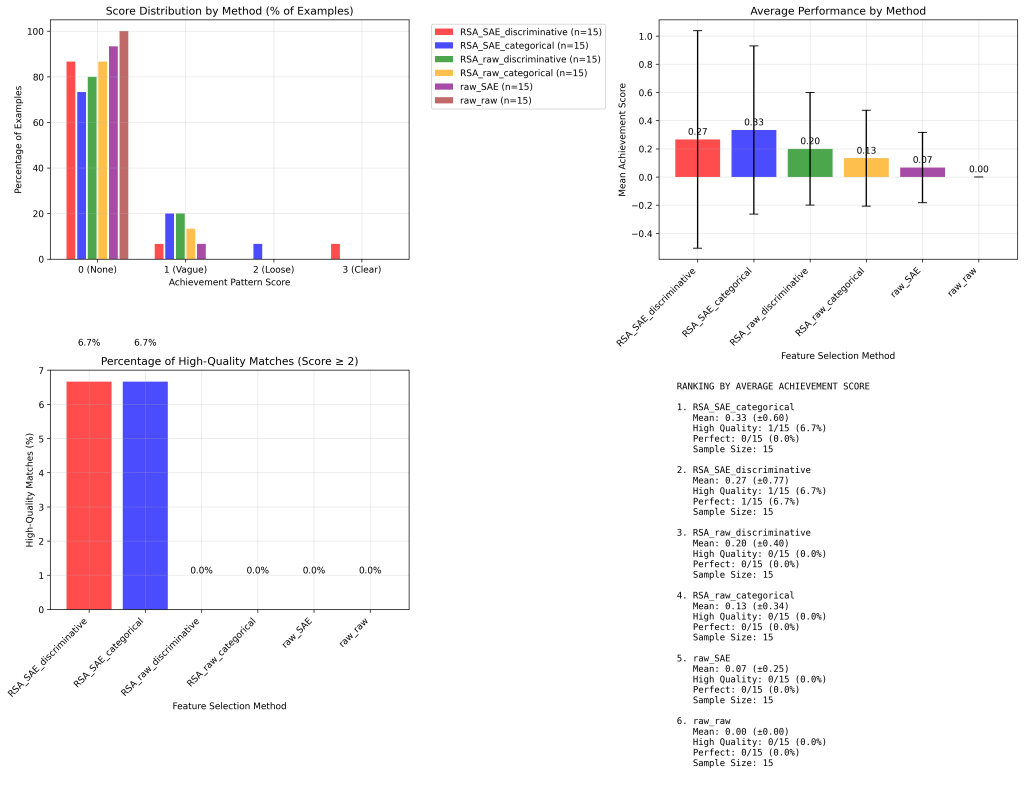
The core challenge is determining which feature selection methods work best when trying to identify neural representations of specific concepts. Six different combinations were tested using Representational Similarity Analysis (RSA) and Sparse Autoencoders (SAE) on achievement vs. failure semantic categories.
Finding summary and conclusions. Key findings suggest that:
- geometric approaches (RSA) outperform simple thresholding (maximum activation),
- SAE decomposition features outperforms raw neural activations,
- and discriminative analysis works better than categorical comparisons
– validating cognitive neuroscience principles when applied to artificial neural networks.
specific tl;dr: Combinatorial analysis of 6 feature selection methods reveals RSA approaches achieve 6.7% high-quality pattern matches while maximum activation methods achieve 0% high-quality matches. RSA_SAE_categorical and RSA_SAE_discriminative emerge as top performers with identical 0.33 mean achievement scores and 6.7% perfect classification rates. The study demonstrates that RSA > maximum activation, SAE > raw layer activations, and discriminative ≥ categorical RSA for semantic concept targeting, though results are preliminary due to small dataset constraints (50 examples per category, 3B parameter model, 50K SAE features).
Note: This was run on a single PC system with a small model and dataset, so overall low accuracy seen on all explored methods so this only represents suggestive signal that discriminative RSA + SAE as the best approach for top-down feature hunting. Larger reproduction would be the next step.
github: https://github.com/omarclaflin/LLM_intrepretability_project
